Обложка: Аэропорт Ларнака 2023
Hints for Computer System Design спустя 40 лет
Однажды я прочитал Operating Systems. Three easy pieces и с тех пор не перестаю рекомендовать эту книгу всем, кто интересуется компьютерами. Читается легко, основные принципы рассмотрены, много примеров. Я сохраняю интересные ссылки из книг и одна из них из этой книги - работа лаурета премии Тьюринга Батлера Лэмпсона Hints for Computer System Design, написанная в 1983, но не потерявшая актуальности и в наше время ИИ и распределенных систем.
Я почитал, позадавал вопросики LLM, попытался вытащить какие-то примеры из современного мира. И записал это для себя. ТАк получился этот пост. Это вольная интерпретация оригинальной статьи, но я очень рекомендую каждому почитать оригинал. Тут будут лишь основные мысли.
Раздел 1. Введение
Хорошие инженеры создают системы, устойчивые ко всем известным проблемам. Лучшие инженеры делают системы устойчивыми к ещё не известным проблемам. Работа Лэмпсона как раз о том, как делать системы быстрыми, устойчивыми и функциональными. Несмотря на то, что написана в 1983, статья актуальна и сейчас. В ней описаны основные принципы с примерами по каждому из них.
Проектирование системы сильно отличается от написания алгоритма. Для алгоритма требования обычно ясны, есть понятный критерий правильности. Для системы же требования размыты и меняются, нет единственно правильного решения и легко построить что-то чрезмерно сложное. Поэтому цель архитектора не найти идеальный дизайн, а избежать ужасных решений и чётко разделить ответственность между компонентами. Проектирование больших компьютерных систем слишком сложно для строгой науки. Поэтому приходится опираться на опыт.
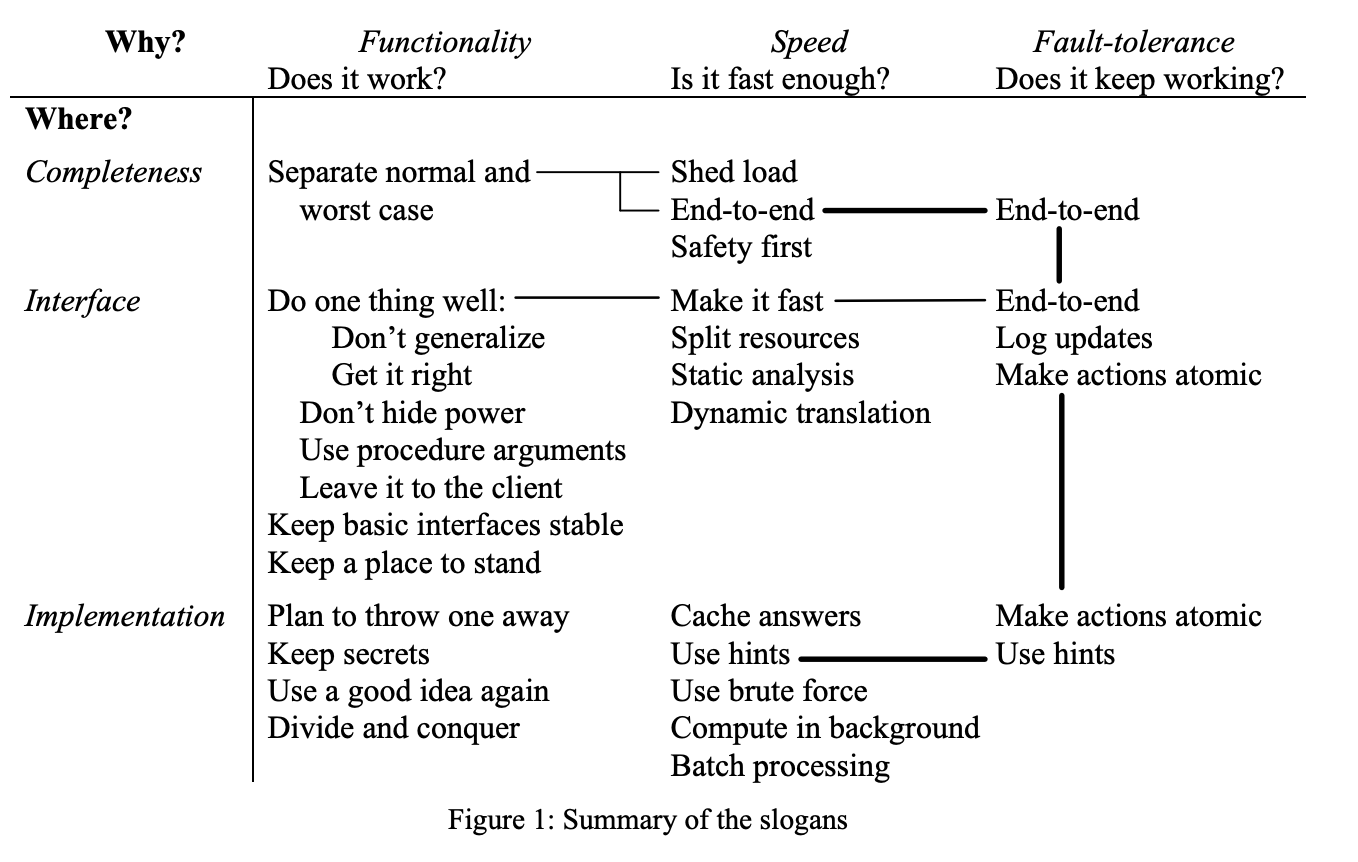
Раздел 2. Функицональность
Интерфейс - важная часть системы. Он должен быть одновременно простым, полным и эффективным. И тут наинаются проблемы: чем больше возможностей, тем сложнее реализация, чем универсальнее интерфейс, тем он медленней, …
2.1 Keep it simple
Глава начинается со слов Антуана Экзюпери: “Совершенство достигается не тогда, когда уже нечего прибавить, но когда уже ничего нельзя отнять”
- Do one thing at a time, and do it well: GNU утилиты прекрасно иллюстрируют этот принцип. Одна утилита делает одну задачу хорошо и быстро
- Интересный пример про Tenex: каждая фича по отдельности выглядит безобидно: trap при обращении к неназначенной странице, передача строк по ссылке, задержка 3 секунды при неверном пароле. Но их комбинация породила изящную дыру: расположив пароль так, чтобы проверяемый символ попадал на границу страницы, атакующий по реакции системы (BadPassword или обращение к неназначенной странице) узнаёт посимвольно правильный пароль. Ни один из проектировщиков не заметил бага, потому что интерфейс системного вызова оказался куда сложнее, чем казалось
▼ Почитайте в оригинале
It reports a reference to an unassigned virtual page by a trap to the user program. A system call is viewed as a machine instruction for an extended machine, and any reference it makes to an unassigned virtual page is thus similarly reported to the user program. Large arguments to system calls, including strings, are passed by reference. There is a system call CONNECT to obtain access to another directory; one of its arguments is a string containing the password for the directory. If the password is wrong, the call fails after a three second delay, to prevent guessing passwords at high speed.
CONNECT is implemented by a loop of the form
for i := 0 to Length(directoryPassword) do
if directoryPassword[i] ≠ passwordArgument[i] then
Wait three seconds; return BadPassword
end if
end loop;
connect to directory; return Success
The following trick finds a password of length n in 64n tries on the average, rather than 128n/2 (Tenex uses 7 bit characters in strings). Arrange the passwordArgument so that its first character is the last character of a page and the next page is unassigned, and try each possible character as the first. If CONNECT reports BadPassword, the guess was wrong; if the system reports a reference to an unassigned page, it was correct. Now arrange the passwordArgument so that its second character is the last character of the page, and proceed in the obvious way.
This obscure and amusing bug went unnoticed by the designers because the interface provided by a Tenex system call is quite complex: it includes the possibility of a reported reference to an unassigned page. Or looked at another way, the interface provided by an ordinary memory reference instruction in system code is quite complex: it includes the possibility that an improper reference will be reported to the client without any chance for the system code to get control first.
- Get it right: Ни абстракция, ни простота не заменят правильного подхода. На самом деле, абстракция может стать источником серьезных трудностей
2.2 Make it fast rather than general
Make it fast, rather than general or powerful: Если операция быстрая, клиент может сам построить нужную ему функциональность. Если операция медленная, клиент вынужден платить за функциональность, которая ему может быть не нужна
- 80% времени приходится лишь на 20% кода: программы тратят бОльшую часть времени на простые операции: сохранить, прочитать, сравнить, добавить единицу. И нужно измерять производительность, чтобы найти эти 20% кода
Don’t hide power: Не скрывай полезные возможности нижнего уровня. Абстракции скрывают детали реализации, но не должны скрывать возможности, которые дает нижний уровень.
Use procedure arguments: Используйте аргументы процедур для обеспечения гибкости интерфейса. Именно этот подход мы используем в GtiLab templates для создания универсальных джоб, способных работать в любом проекте и гибко подстраиваться под требования
Leave it to the client: Если передача управления дешёвая, интерфейс может оставаться простым, гибким и быстрым, решая только одну задачу и оставляя всё остальное клиенту. Опять про GNU: вместо создания монструозных nero-like (nero burning rom - вы поняли о чем я, правда?) утилит, создай десять простых и научи их работать вместе
cat | grep | cut | sort | uniq
2.3 Continuity
- Между желанием улучшать систему и необходимостью сохранять её стабильность всегда существует конфликт
- Когда система вырастает больше чем 250 тысяч строк кода, объём изменений становится невыносимым. Напомню, это наблюдение из 1983. Сейчас число изменилось, но идея осталась та же - микросервисы тому подтверждение
- Keep a place to stand if you do have to change interfaces: иметь простой механизм, который не зависит от сложной системы и позволяет её понять или восстановить. Примеры:
- возможность зайти по SSH на ноду Kubernetes
- etcdctl snapshot
- PostgreSQL physical replication без Patroni
2.4 Making implementations work
Plan to throw one away; you will anyhow:
- если в системе есть хоть что-то новое, первую реализацию придётся переделать полностью, чтобы получить удовлетворительный результат
- Даже успешную реализацию стоит периодически пересматривать
- Пример из жизни: PostgreSQL -> HDD -> оптимизация X. Прошло 10 лет: PostgreSQL -> NVMe -> оптимизация X уже мешает
Keep secrets of the implementation:
- Секреты имплементации — это особенности реализации, которые клиент не знает. Ни к чему Kubernetes Controller Manager знать что происходит под капотом у API Server’a. Главное, чтобы API интерфйс не менялся
- Интерфейс - нельзя менять. Реализацию - можно
- Если клиент не знает как это работает под капотом, то он не будет полагаться на какие-то фичи
Divide and conquer:
- Когда ресурсов не хватает, делай столько, сколько помещается, а остальную работу оставляй на следующую итерацию.
- Иногда полезно искусственно ограничить ресурс: paging вместо сегментации - Фиксированные страницы проще в управлении и уменьшают фрагментацию
Use a good idea again instead of generalizing it: переиспользуй хорошие идеи, не превращай их в универсальные
2.5 Handling all the cases
- Handle normal and worst cases separately as a rule: Обрабатывай нормальный и худший случаи по-разному
- normal - должно быть быстро
- worst - должна гарантированно сохраняться возможность двигаться вперёд. Не быстро, не красиво, не оптимально. Прсото двигаться
- Не стоит жертвовать производительностью нормального случая ради идеального поведения в крайне редком сценарии
Во многих системах нормально иногда быть несправедливым, не обслуживать часть процессов или даже получить дедлок всей системы, если это автоматически обнаруживается и редко происходит. Один краш в неделю может быть разумной ценой за 20% производительности. Сейчас это звучит дико, но сути это не меняет: не стоит жертвовать производительностью нормального случая ради идеального поведения в крайне редком сценарии.
Примеры:
- Если известно, что рано или поздно придется делать дефрагментацию данных, то можно запланировать ее на часы наименьшей нагрузки ежедневно. Так процесс получится ожидаемым и контролируемым
- reserved memory в ядре Linux, connection reserve в БД, свободное место на диске под recovery
- compaction в LSM, ClickHouse merges;
Раздел 3. Производительность
Split resources: если есть сомнения, то разделяй ресурсы в заранее известном формате вместо переиспользования. Обычно проще и быстрее выделить конкретный кусок ресурса, чем переиспользовать общее.
- Современный пример: Node Pools: worker/ingress, PostgreSQL Read Replicas
Use static analysis if you can. Не пеерсчитывать результат каждый раз, если не меняются вводные.
- Всё, что можно определить заранее, следует определить заранее. Рантайм должен выполнять работу, а не размышлять о том, как её выполнять
- Статический анализ особенно хорош тогда, когда стоимость подготовки платится один раз, а выгода получается много раз
- Современный пример: Helm Template делается до примненеия, SQL Planner, Terraform plan
Dynamic translation: динамическая трансляция из удобного вида в что-то более удобное для машины для дальнейшего быстрого переиспользования. Примерно то, что делают компиляторы.
- Примеры: JIT переводит байт-код в машинный код при первом вызове процедуры и кэширует результат - дальше выполняется уже машинный код, regex сначала компилируется, потом выполняется
Cache answers: кэшировать результаты дорогих операций, вместо повторения этих операций
- Главная проблема кэша — не сохранить ответ, а понять, когда он перестал быть правильным
- Не делай одну и ту же работу дважды! Это, кстати, перекликается с static analysis
Use hints. Hint это почти то же, что кэш, но результат хинта может быть неверным (surpise!)
- Держи быстрые, возможно неточные структуры данных, если существует надёжный источник истины, по которому их можно проверить и восстановить
- Поскольку hint может быть неправильным, должен существовать способ проверить его корректность перед выполнением необратимого действия. Проверка производится относительно “truth” — данных, которые обязаны быть правильными
- Truth: медленный, неудобный, дорогой. Но всегда правильный
- Hint: быстрый, удобный, может устареть, может быть ошибочным
- Если hint неправильный - считаем заново
- Примеры: Ethernet (Вспоминаем, что работа 1983 года). Если сигнала нет (hint), то можно начинать передачу. Но так могут посчитать два девайса в одном домене коллизий, каждый отправляет данные и поулчается коллизия. Каждый определяет коллизию (проверка) и засыпает на рандомное время (fix)
- DNS cache - тоже hint. Система читает записи из своего кэша, они уже могут быть устаревшими. Но у каждой записи есть TTL
When in doubt, use brute force: Если сомневаешься — используй грубую силу. Простое решение, которое легко понять и проанализировать, обычно лучше сложного умного решения, работающего только при выполнении множества предположений
- Буквально как решаются проблемы производительности в современном мире. Мало кто задумывается об оптимизации кода - берем железо помощнее - проблема решена
Compute in background: Делай работу в фоне, до того как она понадобится клиенту
- Большинство систем загружены неравномерно. Поэтому можно использовать периоды наименьшей загруженности для выполнения тяжелых операций, которые точно понадобятся в будущем
- PostgreSQL Vacuum, ClickHouse MergeTree, индексация данных, Garbage Collection
Batch processing: Если нужно выполнить много похожих операций, обычно выгоднее обрабатывать их группой, а не по одной
- Часто стоимость запуска операции больше, чем стоимость обработки дополнительного элемента внутри этой операции
- Но если батчи слишком большие, то это может вызвать проблемы: Latency, вероятность ошибок, повышенное потребление памяти
- Алгоритм Нейгла в TCP идеально иллюстрирует это - вместо отправки ста пакетов по одному байту, он накопит байты, пока не получит TCP MSS, пакует всё в один пакет и отправляет 1, 2
Safety first: чрезмерное потребление ресурсов может привести к проблемам, поэтому при управлении ресурсами важнее оставить запас и избежать катастрофического режима, чем добиться максимальной утилизации
- Использование >2/3 может снижать производительность системы: например, у ZFS после 80% ратсет фрагментация
- Железо дешевое - можно залить проблему железом. Отсылка к When in doubt, use brute force
- Пример: когда память была дорогой, инженеры пытались выжать максимум из алгоритмов: размещать связанные процедуры на одной странице, предсказывать следующие обращения, подбирать совместимые задачи, умно управлять swap. Потом память подешевела и на эти отпимизации просто перестали тратить силы
- Cвободное место в ClickHouse для merge, PgBouncer вместо множества backend-процессов
Shed load to control demand: Система не может нормально работать, если спрос на какой-либо ресурс превышает его возможности. По сути это продолжение предыдущего утверждения
- Лучше отказаться от части работы чем пытаться выполнить всё
- Пример: HTTP 429 Too Many Requests, Pod Pending когда недостаточно ресурсов, Circuit Breaker в OpenSearch
Раздел 4. Отказоустойчивость
Неизбежная цена надежности - простота C.A.R. Hoare
Сделать систему надёжной не так уж трудно, если думать об этом с самого начала. А вот добавить надёжность в уже существующую архитектуру чрезвычайно сложно
Не пытайся сделать каждый компонент идеальным. Построй систему так, чтобы она могла обнаруживать ошибки, восстанавливаться после них и продолжать работу:
- TCP предполагает потерю пакетов
- Raft предполагает падение узлов
- Kubernetes предполагает смерть подов
- PostgreSQL WAL предполагает аварийное завершение процесса
- Kafka предполагает выход брокеров из строя
End-to-end: проверить правильность операции может только само приложение
- Передаем файл по сети: Диск проверил CRC - Сеть проверила checksum - TCP подтвердил доставку - ОС ошибок не вернула - значит всё хорошо?
- Не-а! По пути могло быть много ошибок. Банально, где-то по пути (сеть или RAM или запись на диск или bad block диска или ошибка драйвера или …) мог потеряться или измениться один бит
- Поэтому конечное решение о корректности операции должно принимать приложение. В нашем случае можно сравнить чексуммы файлов
- Но есть нюанс, Петька! Если полагаться только на конечную проверку и не использовать промежуточные механизмы обнаружения ошибок (CRC, ECC, checksums), то стоимость восстановления после ошибки может оказаться слишком высокой. Именно поэтому промежуточные проверки нужны — но как оптимизация производительности, а не как замена проверки на уровне приложения
- Принцип, описывающий почему бэкапы надо проверять
Log updates: источник истины - журнал изменений, а не текущее состояние объекта
- Лог: записывается только в конец, требует минимум операций записи, легко сделать корректным даже при аварийном завершении, легко копировать, легко сохранять на ленту или другой носитель. По сравнению с произвольным обновлением структуры данных это огромный выигрыш.
- По логу легко воспроизвести все операции
- Но есть нюанс, Петька! Записи в логе должны должны быть идемпотентны:
balance(user) = balance(user)+50VSset_balance(user, 150) - Всё современное ИТ работает на этом принципе: WAL logs в БД, git, etcd в кубере
Make actions atomic or restartable: Атомарное действие либо завершается полностью, либо не оказывает никакого эффекта. По сути - определение транзакции
- транзакции должны быть атомарны и идемпотентны, то есть при повторном выполнении давать тот же результат, как в примере выше про баланс
Заключение
Основные идеи статьи:
- Делай систему проще
- Не выполняй одну и ту же работу дважды
- Переноси тяжёлую работу из критического пути пользователя
- Храни один источник истины, а всё остальное считай производными структурами
- Проектируй систему, исходя из неизбежности сбоев
В момент написания этого поста я узнал, что есть обновленная версия документа от 2020 года (в четыре раза толще первой работы - 106 страниц вместо 27)