DHCP сервер - одна из наиболее критичных служб сетевой инфраструктуры. Он обычно прост в настройке и не привлекает к себе внимание до того момента пока в сети не начинаются непонятные моменты: машины не получают адреса или получают, но совсем не те, которые хотел бы администратор. Вследствие чего сеть просто перестает работать.
В этой статье попробуем создать отказоустойчивый DHCP сервер на Mikrotik RouterOS.
Для понимания работы системы системы нужно сначала понять принцип работы самого протокола. Тем, кто и так это знает, следующий пункт можно не читать.
Принцип работы протокола DHCP
При включении хоста, его DHCP клиент производит broadcast рассылку DHCPDISCOVER на адрес 255.255.255.255, в которой указывает свой MAC адрес в качестве адреса отправителя. В ней хост пытается найти DHCP сервер в своем сегменте. Этот пакет долетит до всех хостов в сети.
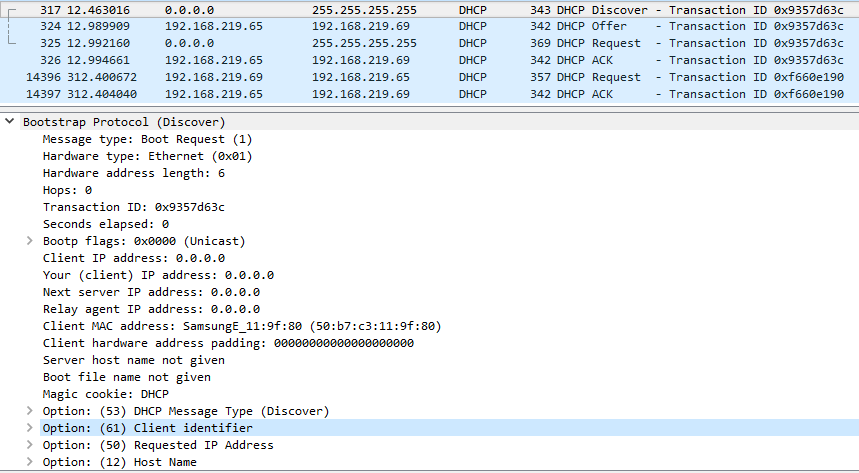
Здесь нас интересует поле Client MAC Address. Именно ему будет отвечать сервер.
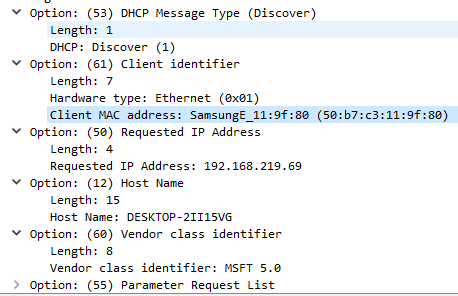
Когда этот пакет долетает до DHCP сервера, тот отвечает на запрос пакетом DHCPOFFER, в котором сообщает свой IP адрес, предполагаемый адрес клиента и другие параметры, такие как адреса DNS серверов, NTP, WINS и другие.
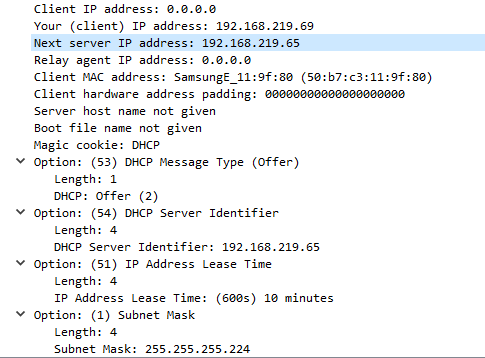
Важным параметром здесь является параметр Lease Time: это время в секундах, на которое сервер выдает клиенту адрес. По истечении этого времени клиент должен запросить аренду снова. Как это происходит рассмотрим чуть ниже.
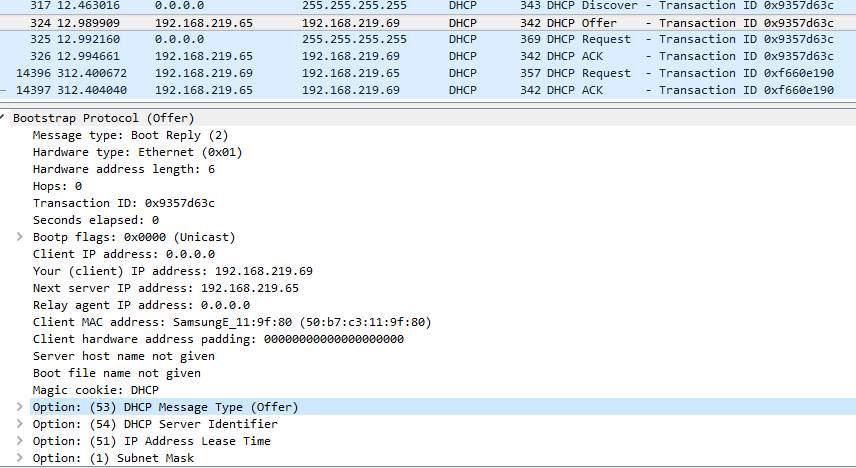
Затем клиент обрабатывает OFFER и посылает на широковещательный адрес 255.255.255.255 DHCPREQUEST, где спрашивает разрешение у сервера использовать предложенный им (сервером) адрес и сообщает другим серверам о том, что выбран нужный сервер и адрес. Этот пакет долетит до всех хостов в сети.
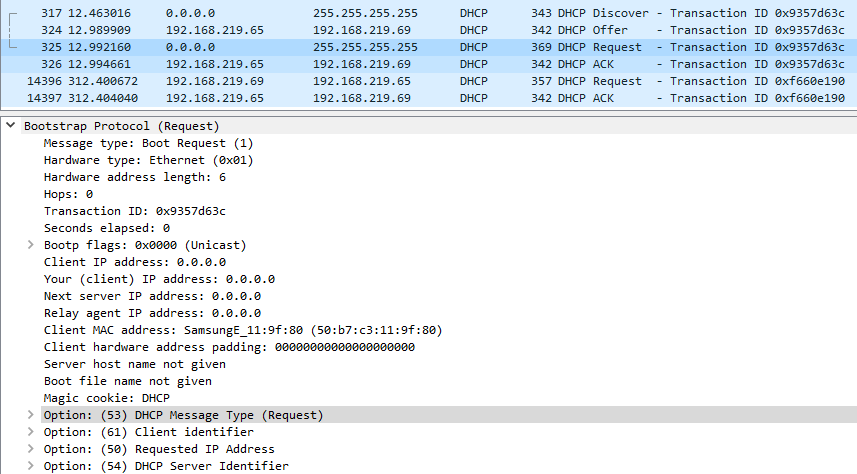
В поле Requested IP Address клиент запашивает IP адрес, который он хочет использовать.

В ответ сервер отвечает пакетом DHCPACK, в котором подтверждает использование выбранного адреса.
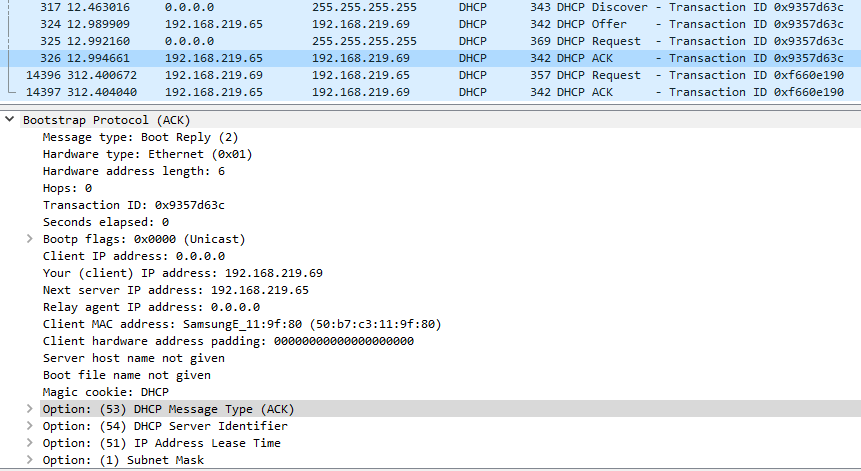
Этот пакет отсылается уже с IP адреса сервера на IP адрес клиента.

Весь процесс выглядит так:
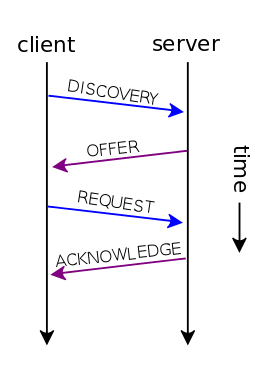
По истечении половины Lease Time клиент отсылает серверу пакет DHCPREQUEST, в котором просит продлить время аренды на Lease Time, на что сервер должен ответить DHCPACK, если разрешает клиенту использовать запрошенный адрес. Или DHCPNACK, если не разрешает. Процесс повторяется через каждую половину Lease Time.
В случае, если сервер не подтвердит использование этого адреса, клиент ждет ещё половину Lease Time и начинает процесс самого начала: освобождает свой адрес и ищет DHCP сервер, с помощью пакета DHCPDISCOVER.
Настройка отказоустойчивости DHCP в Mikrtoik
О настройке DHCP сервера и клиента в Mikrotik RouterOS сказано немало. В том числе, в курсе Mikrotik Certified Network Associate - MTCNA. Здесь не будем рассматривать типичную настройку, а коснемся некоторых нюансов для обеспечения отказоустойчивости.
Чтобы обеспечить отказоустойчивость сервиса DHCP можно просто развернуть в одной сети несколько DHCP серверов. Тогда клиент будет получать адрес от того сервера, который первым ответит на DISCOVER. Но тут возникает проблема: несколько клиентов могут получить один и тот же адрес и никто из них не сможет нормально работать.
Выход напрашивается такой: раздавать адреса из разных пулов. К примеру, один сервер будет раздавать адреса из пула 192.168.0.0/25, а второй - из пула 192.168.0.128/25. Тогда мы покрываем работоспособность всей сети 192.168.0.0/24. Но что произойдет, если один из DHCP серверов откажется работать? Тогда работать будет лишь одна часть сети - 192.168.0.0/25 или 192.168.0.128/25. Полной отказоустойчивости не получим.
На помощь приходит параметр Delay Threshold. В wiki Mikrotik сказано:
Если поле secs в DHCP пакете меньше, чем параметр delay-threshold, то пакет игнорируется DHCP сервером. Если параметр установлен в none - все пакеты будут обрабатываться.
В пакетах DHCPREQUEST и DHCPDISCOVER есть поле Seconds, описывающее время, прошедшее с момента начала активности клиента.
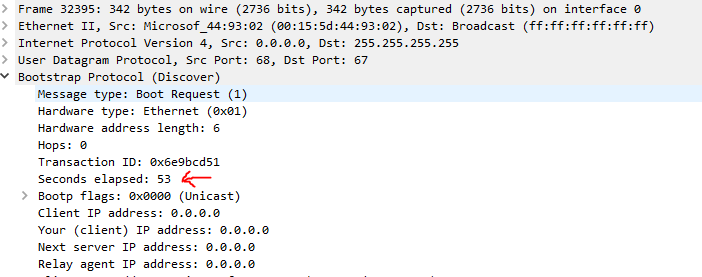
Дело в том, что при отсутствии ответа от сервера, клиент не успокаивается на одном запросе. Он будет слать запросы к серверу с экспоненциальным ростом задержки, чтобы не зафлудить своими сообщениями сеть и при этом ещё пытаться получить DHCPACK или DHCPOFFER.
Так вот параметр delay-threshold проверяет поле seconds elapsed пакета DHCPREQUEST, и если количество секунд, указанное в этом поле меньше значения delay-threshold, то сервер просто игнорирует такие пакеты. А если больше, то отвечает на них.
Если установить у DHCP сервера delay-threshold=30, то клиент сможет получить DHCPOFFER, а следом за ним и свой адрес в DHCPACK, только по истечении 30 секунд после первого запроса.
Тут стоит заметить, что в RouterOS 6.39.2, на которой я провожу эксперименты, delay-threshold влияет только на пакеты DHCPDISCOVER.
Значит, можно разместить в одной сети два абсолютно идентичных DHCP сервера, указав у них разные параметры delay-threshold. У одного выставим в none, у второго в 10 секунд. Это значит, что первый сервер будет обрабатывать все запросы, а если он перестанет отвечать, то каждый запрос, “протухший” на 10 секунд будет обработан вторым сервером.
Если быть точнее, то произойдет следующее:
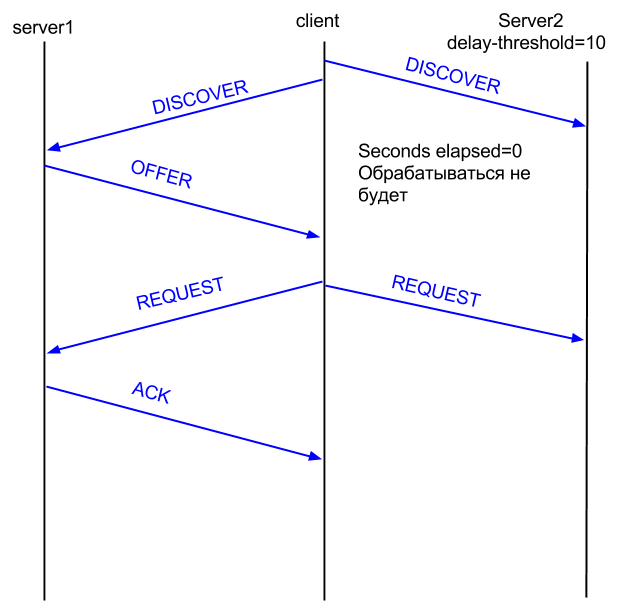
- Client —> DHCPDISCOVER —> broadcast
Этот пакет долетит до обоих серверов, но так как seconds elapsed=0, то ответит только тот сервер, у которого delay-threshold=none
Server1 —> DHCPOFFER —> broadcast
Client —> DHCPREQUEST —> broadcast
Server1 —> DHCPACK —> client
Прошло lease-time/2. Server1 ещё жив
Client —> DHCPREQUEST —> server1
Время аренды адреса продлилось до lease-time
- Server1 —> DHCPACK —> client
Где-то в этом промежутке сервер умер
Прошло lease-time/2.
- Client —> DHCPREQUEST —> server1
Этот пакет server1 не получит, потому что он умер. А до второго сервера пакет не долетит, так как предназначался первому и в dst-addr пакета указан только адрес server1
Через несколько миллисекунд
- Client —> DHCPREQUEST —> server1
Прошло ещё какое-то время и клиент сделал ещё несколько DHCPREQUEST’ов.
Прошло ещё lease-time/2 после пункта 7
- Client —> DHCPDISCOVER —> broadcast
Этот пакет не долетит до мертвого server1, но долетит до живого server2. Но обработан им не будет, так как elapsed seconds<10
Ещё несколько пакетов DHCPDISCOVER ждет такая же судьба, как и 9. Пока не пройдет 10 секунд с пункта 9
Client —> DHCPDISCOVER —> broadcast
В этом пакете elapsed seconds=>10, а значит, его обработает server2
Server2 —> DHCPOFFER —> client
Client —> DHCPREQUEST —> broadcast
Server2 —> DHCPACK —> client
И всё по новой
Чего мы добились?
Если перестает отвечать один из серверов, то его обязанности берет на себя резервный сервер и продолжает поддерживать работу сети. При этом адреса, полученные клиентами, останутся при них, потому что протокол позволяет клиентам запрашивать определенный адрес, который обычно остается за интерфейсом.
Но что произойдет, если первый сервер вернется в работу? Клиенты продолжат работать со вторым, так как именно он отвечал им в DHCPACK. Казалось бы, такая ситуация нас вполне устраивает. Если бы не статические записи в таблице Leases, которые, как правило выдаются серверам или важным пользователям, чтобы применять к ним правила фаервола или шейпинга.
Допустим, первый сервер отказал ночью. Пользователи пришли на работу, включили компьютеры. А те начали запрашивать адреса у DHCP сервера. Но дизайнер может прийти раньше директора и получить у нового сервера VIP адрес. Ведь новый сервер ещё ничего не знает о статических записях. А директор в свою очередь, получит адрес секретарши, к IP адресу которой привязаны самые жесткие ограничения.
Значит, необходимо как-то синхронизировать базы данных DHCP серверов. В этом нам помогут замечательные скрипты RouterOS.
Основный сервер должен выгружать список адресов для аренды в файл:
if (\[:len \[/file find name=leases.rsc\]\]>0) do={/file remove leases.rsc}
/ip dhcp-server lease export file=leases.rsc
Вводим этот скрипт в планировщик. Выполняем задачу с нужной нам периодичностью.
На этом же роутере создадим группу FTP с правами ftp, read. И пользователя с таким же именем. Он будет нужен, чтобы резервный сервер мог скачать список leases.rsc
На резервном сервере в планировщик внесем скрипт, который скачивает список с основного сервера, чистит список адресов и импортирует его из файла.
if (\[:len \[/file find name=leases.rsc\]\]>0) do={/file remove leases.rsc}
/tool fetch mode=ftp address=192.168.1.1 src-path=leases.rsc user=FTP password=http://bubnovd.net
if (\[:len \[/file find name=leases.rsc\]\]>0) do={
foreach i in=\[/ip dhcp-server lease find \] do={
/ip dhcp-server lease remove $i
};
import leases.rsc;
}
Теперь списки адресов будут синхронизироваться между серверами с той периодичностью, которая будет указана в планировщике. Я не рекомендую делать это слишком часто, так как любая запись на флеш роутера приближает её на шаг ближе к смерти.
Казалось бы задача выполнена. Служба DHCP зарезервирована. Сервера обмениваются информацией о статических записях. При поломке одного из серверов, всю работу берет на себя второй. После выключения хоста или при новом запросе DHCPDISCOVERY, хост переключается на основной сервер.
Осталось одно маленькое неудобство. Скрипт, написанный ранее, синхронизирует записи server1 с server2. То есть, основная актуальная копия БД находится на одном сервере и все изменения, проделанные на server2 не будут реплицированы на server1. А вручную перебивать записи - не наш путь.
Можно, конечно, залить точно такой же скрипт на второй сервер и настроить их совместную работу. Но мы пойдем по другому пути.
Сделаем так, чтобы при включении в работу основного сервера, все клиенты в кратчайшее время перебрасывались на него и использовали актуальную версию базы адресов.
Этот метод не описан в RFC, и, вполне возможно, противоречит ему. Используйте на свой страх и риск!!! У меня работает =)
Для этого необходимо обмануть клиентов, указав в качестве src-addr DHCP сервера, адрес server1 даже если пакет улетает с server2. Тогда при операции DHCPREQUEST клиент будет всегда обращаться к server1. А если он не отвечает, то по истечении lease-time, будет инициирован DHCPDISCOVERY, на который после 10 секунд ответит второй - бэкапный сервер. И все клиенты будут возвращаться с бэкапного сервера на основной по истечении lease-time/2. И наоборот после lease-time.
В этом нам поможет параметр src-address. На резервном сервере укажем в качестве src-address адрес первого сервера и наслаждаемся отказоустойчивостью!
На этом всё! Служба DHCP зарезервирована. При отказе любого из DHCP серверов сеть продолжает работать, статические записи аренды синхронизируются. Конечно, тут мы не решили проблему отказа шлюза, но это не входило в тему поста. Поговорим об этом в следующих постах.
Приходите ко мне на курсы по Mikrotik!
Дополнения.
В ходе тестирования этого решения было замечено, что некоторые клиенты (телефоны Yealink) иногда в пакетах DHCPREQUEST указывают значение seconds elapsed=100. Благодаря чему могут получить адрес с резервного сервера, при живом основном. Лечится ребутом девайса.
На резервный сервер неплохо было бы прикрутить оповещение админа о том, что он начал выдавать адреса. Ведь если резервный начал выдавать адреса, значит основной не работает и его кто-то должен починить. Оповестить админа можно с помощью логов, отправленных на syslog сервер и обработанных должным образом, либо с помощью скрипта в lease-script. Первый способ мне кажется более предпочтительным и правильным.
UPD: 18 июля был опубликован этот пост, а 25 на хабре вышла интересная статья об атаке на DHCP с изложением принципов работы